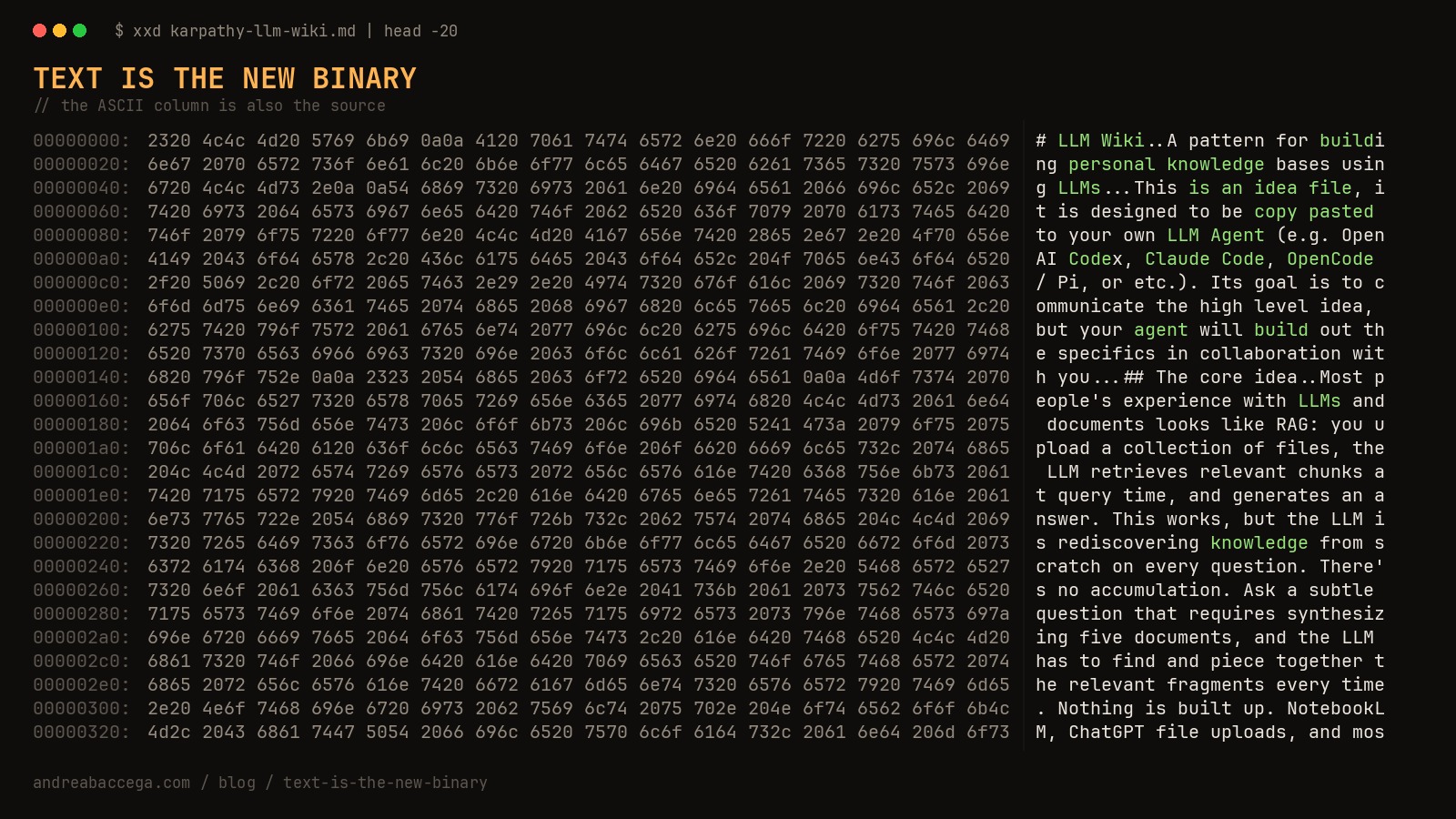
In April 2026, Andrej Karpathy published a GitHub gist. Not code. Not a library. A markdown document describing a pattern: an LLM-maintained folder of wiki pages that compounds across sessions and beats RAG. Right at the top, he tells you exactly what kind of artifact it is:
“This is an idea file, it is designed to be copy pasted to your own LLM Agent (e.g. OpenAI Codex, Claude Code, OpenCode / Pi, or etc.). Its goal is to communicate the high level idea, but your agent will build out the specifics in collaboration with you.”
Within weeks: tutorials, v2 forks, “beyond RAG” think-pieces, dozens of open-source implementations. People are running this software. The artifact is prose. There’s no npm install, no version, no test suite. You read the gist, you instruct your agent, your agent builds you a wiki.
I’m running it too. That’s a binary.
The Reframe
Code is what you write. A binary is what you ship: the thing users actually execute. Software used to ship as compiled artifacts with contracts: function signatures, exit codes, semver, reproducible builds. A growing class now ships as text meant to be interpreted by someone else’s LLM at runtime. No types. No version pin (which model? which context window? which mood?). No tests in the old sense. Just words and trust.
Text is shipped. Text is executed. Text is the binary.
Even the Installation is Text
For decades, the “installation” section of a README was one of two things: a shell command, or a config file. npm install foo. curl … | bash. docker pull. A deterministic instruction the human (or CI) executes verbatim.
Now look at the install for awesome-agent-skills, an April 2026 directory of skills for Claude, Codex, and Copilot:
“paste the raw SKILL.md URL in a new conversation. […] That’s it. No installation. No configuration. No coding required.”
Read that again. The install command is a sentence in English: “paste the raw SKILL.md URL in a new conversation.” There’s no script. There’s no package. There’s a markdown file at a URL, and a paragraph telling you to hand the URL to your agent, which then reads the markdown and figures out the rest. The install instruction is prose; what it points to is prose; what the prose configures is the agent’s behavior at runtime. It’s prose all the way down.
Karpathy’s gist is the same shape: “copy paste this to your own LLM Agent” is the install command. So is every CLAUDE.md and every AGENTS.md, now a Linux Foundation standard adopted across 60,000+ projects1: project configuration shipped as prose, no installer required. GitHub even shipped gh skill install2 in April 2026, a first-class CLI command for installing markdown files.
This isn’t a fad. It’s a real engineering shift, with reasons:
- Forkability. Edit a paragraph, you have a v2.
- Model evolution. The same prose gets sharper as the agent does.
- Personalization at runtime. Don’t like something about Karpathy’s gist? Add a line to your prompt. Specific need your team has? Just tell the agent. Every reader of the same prose gets their own build, shaped by what they say next. No binary can do that.
The Format is Markdown
Notice how everything in the previous section is markdown. Karpathy’s gist, AGENTS.md, SKILL.md, the blog post you’re reading. That’s not an accident; it’s becoming the substrate.
In February 2026, Cloudflare shipped Markdown for Agents:
“Markdown has quickly become the lingua franca for agents and AI systems as a whole.”
Any site behind Cloudflare can now serve a markdown version of itself when the request includes Accept: text/markdown. Claude Code and OpenCode already send that header. Cloudflare’s own measurement: a blog post costs 16,180 tokens as HTML, 3,150 as markdown. An 80% reduction. The web is starting to translate itself.
If text is the new binary, markdown is its instruction set.
When the App Is the File
The escalation continues. If installation is prose and the format is markdown, entire products start collapsing into markdown files.
In 2015, “track what I eat today” required someone to build you an app: a developer, a designer, a backend, an App Store listing. Months of work, thousands of dollars. In 2026, it’s a sentence to an agent. No download, no onboarding, no app.
Karpathy frames this arc as Software 3.03: code (1.0) → learned weights (2.0) → prompts (3.0). One-shot work doesn’t even need an artifact: you say what you want and the agent does it. Recurring work gets a markdown file so you don’t re-explain. Only the rest still wants code. People are already shipping “skill graphs”: folders of interlinked markdown that teach an LLM how to think about a domain, sold not as a SaaS but as a folder you own. “Apps gave phones superpowers; skills give AI agents expertise.”4
This won’t replace every app. It will replace the long tail whose only real value was encoding a workflow. Personalization stretches the tail further: when generating a custom version for one user is cheap, the market for one-size-fits-all SaaS shrinks5. That tail is enormous.
The Paradox Karpathy Spotted
Here’s the irony hiding inside Karpathy’s own gist. The whole thesis of the LLM Wiki is a critique of how today’s RAG systems handle knowledge:
“the LLM is rediscovering knowledge from scratch on every question. There’s no accumulation. […] The knowledge is compiled once and then kept current, not re-derived on every query.”
But “text as binary” is structurally identical to RAG. The agent re-interprets the same prose every time: every CLAUDE.md loaded into a new session, every SKILL.md matched against a prompt and read into context. The same critique that pushes Karpathy beyond RAG will eventually push us beyond text-as-binary for the workloads where re-derivation is too expensive: high frequency, low margin, regulated, audited.
That’s the real shape of the next few years. We’re in an exuberant phase. Text-as-binary is shipping into places it’ll eventually retreat from. Try debugging an agent that decided to skip a step in your workflow, or auditing a refund issued because a CLAUDE.md said “be helpful.” Meanwhile the deterministic binary is still sitting in places it’ll eventually cede: every workflow that’s 80% similar to one you support but not exactly.
The fight is loud because the equilibrium hasn’t arrived yet. Both approaches are oversold and underspecified at the boundary. That’s a temporary condition.
Where the Line Lands
A heuristic:
- Text wins when the surface area is infinite and correctness is fuzzy.
- Code wins when the contract is auditable, the bill is real, or re-derivation is too expensive.
Most production systems will need both: text at the edges (interpretation, dispatch), code in the core (execution, money, security). The interesting engineering of the next five years isn’t picking sides. It’s finding where the line falls for your specific problem.
This blog is a worked example. You’re reading prose: a markdown file in a src/content/blog/ folder, compiled to HTML by Astro at build time. Text at the edge (the writing), deterministic code at the core (the build pipeline). No LLM mediating the runtime. The line falls there. For my CLAUDE.md, it falls somewhere else. For Karpathy’s gist, somewhere else again.
Karpathy himself flags this in the closing of the gist:
“The document’s only job is to communicate the pattern. Your LLM can figure out the rest.”
That sentence is doing two things at once. It’s a confession that the artifact has limits. And it’s a bet that, for this workload, the limits are worth the leverage. Both can be true. That’s where the line will eventually land, not on text or code, but on which one carries the leverage worth its limits, for the problem in front of you.
Footnotes
-
AGENTS.md was originally popularized by OpenAI’s Codex CLI and was donated to the Linux Foundation’s Agentic AI Foundation in December 2025 as one of three founding projects (alongside Anthropic’s Model Context Protocol and Block’s goose). Adopted across 60,000+ open-source projects and agent frameworks. ↩
-
GitHub’s
gh skill installchangelog, April 16, 2026. ↩ -
Andrej Karpathy, “Software 3.0,” YC AI Startup School keynote, 2025. Latent Space transcript and discussion. ↩
-
From “AI Skills Are the New Apps”, OpenClaw, 2026. ↩
-
Software ETFs fell roughly 30% in early 2026, with Salesforce, Adobe, and ServiceNow each off 25-30%. Analysts are calling it “AI eating software.” See Fortune’s coverage of the SaaSpocalypse and a16z’s “Notes on AI Apps in 2026”. ↩